The Project
Idea and Requirements

Why an Ontology about Sampling?
Everything started with a few questions:
- Can we use knowledge representation and extraction methods to describe the logic and semantics of sampling within modern music production practices?
- Can we effectively express which songs — or, indeed, parts of songs — have been used in order to create a new piece of music?
- Can we describe the transformation process of a song element into a sample via manipulation?
Extending the Music Ontology and reusing WhoSampled
The primary starting point for SamO was the WhoSampled website, which is the most popular online repository for sampling data today. WhoSampled used to have an open API, however it was deactivated sometime in the late 2010s and closed off to enable the company to use the data for commercial purposes. Because of this we were unable to get a clear idea of how WhoSampled organizes their data, though we assume that there is some sort of ontological categorization, semantic taxonomy, or detailed metadata at work. Furthermore, their decision to commercialise the data is problematic in that this data originates from public contributions, as evidenced on individual sample pages, and may also originate from earlier web1 efforts by fans to create free, public sampling directories (much in the same way Genius, the most popular lyrics repository today, used web1 directories to kickstart its website).
As Catherine D’Ignazio and Lauren Klein explain in chapter 7 of Data Feminism, "Data work is part of a larger ecology of knowledge, one that must be both sustainable and socially just. […] the network of people who contribute to data projects is vast and complex. Showing this work is an essential component of data feminism […]."1 While WhoSampled has kept public the contributions made by the public over the years, their move to commercialize this data is clearly problematic in how it extracts capital potential from a publicly-built dataset without any say from the contributors. With this in mind, we wanted to try and replicate some of the public facing semantics/logic of WhoSampled in an open ontology, so as to potentially free up this data once more.
For the development of the ontology itself, the main point of reference was the Music Ontology (MO), created back in 2007 and to this day still the primary ontology for music-related events and concepts. We also used the Audio Commons Ontology as an early point of reference. After studying the documentation and literature around these two ontologies, we decided that it would be best to take advantage of some of the already existing classes and predicates within MO to essentially extend it. Extending and reusing existing ontologies whenever possible is best practice to ensure the overall interoperability of Linked Open Data and avoid the creation of redundant ontological elements across different, related ontologies.
While MO does refer to concepts of sampling, the creation of a specific module for dealing with sampling was suggested among its possible future improvements in its 2007 paper. It was clear upon closer study that their existing approach did not satisfy our requirements and so we decided to create classes and predicates needed specifically to deal with sampling while keeping some MO elements as a foundation, in particular their own extension of the four levels of representation as conceptualized by the IFLA's Functional Requirements for Bibliographic Records (FRBR).
1. Show Your Work. (2020). In Data Feminism. Retrieved from https://data-feminism.mitpress.mit.edu/pub/0vgzaln4
Preliminary Development and Competency Questions
We decided to develop SamO using a bottom-up approach, that is beginning with data from WhoSampled to shape the structure of the terminology component of our ontology (TBox). We started by selecting 20 relationships (10 each) from WhoSampled that featured a jazz song being used as a sample in a hip-hop or electronic music song. The focus on jazz as a source genre was due to early conversations about focusing the ontology on the specific relationship between sampling jazz in hip-hop, however we ultimately decided to not limit the focus of our ontology though we kept the themed dataset.
The next step was formulating a set of primary Competency Questions. These would be natural language questions designed to help us understand what SamO should be able to represent and what a user should be able to extract from it.
The final preliminary step in our ontology development was to take a closer look at both the MO and Audio Commons ontologies to best understand how the concept of sampling had already been described. Audio Commons was chosen because it deals with describing audio contents within online libraries, including samples which it considers as equivalent to tracks under a wider concept of an audio clip class. Ultimately this approach proved to not be suited to our needs however by studying it we were able to get a better understanding of how to structure SamO.
Below are examples of some of the main generic competency questions we settled on. Detailed examples of the same questions, as well as others which were devised after the ontology was built, and their equivalent SPARQL results are given in the Competency Questions section.
Initial Competency Questions
How many samples are present in a song?
Which songs are sampled in another song?
Which songs of a specific genre are used as samples?
What are the different types of samples?
Which songs by a specific artist have been used as a sample?
Which song(s) use(s) samples that have been manipulated in a certain way?
What are the different types of sampling manipulation?
Which songs released within a timespan have been used as a sample?
What are the different types of elements within a song that can become a sample?
DOCUMENTATION
The Conceptual Map
Following the preliminary development steps we focused on creating a conceptual map to better distinguish and understand which classes, predicates, data, and object type properties were needed. Over the course of multiple conversations we discussed how deep the model should go and which key concepts were essential. At this stage we also made extensive reference to the MO, FRBR, and Audio Commons models.
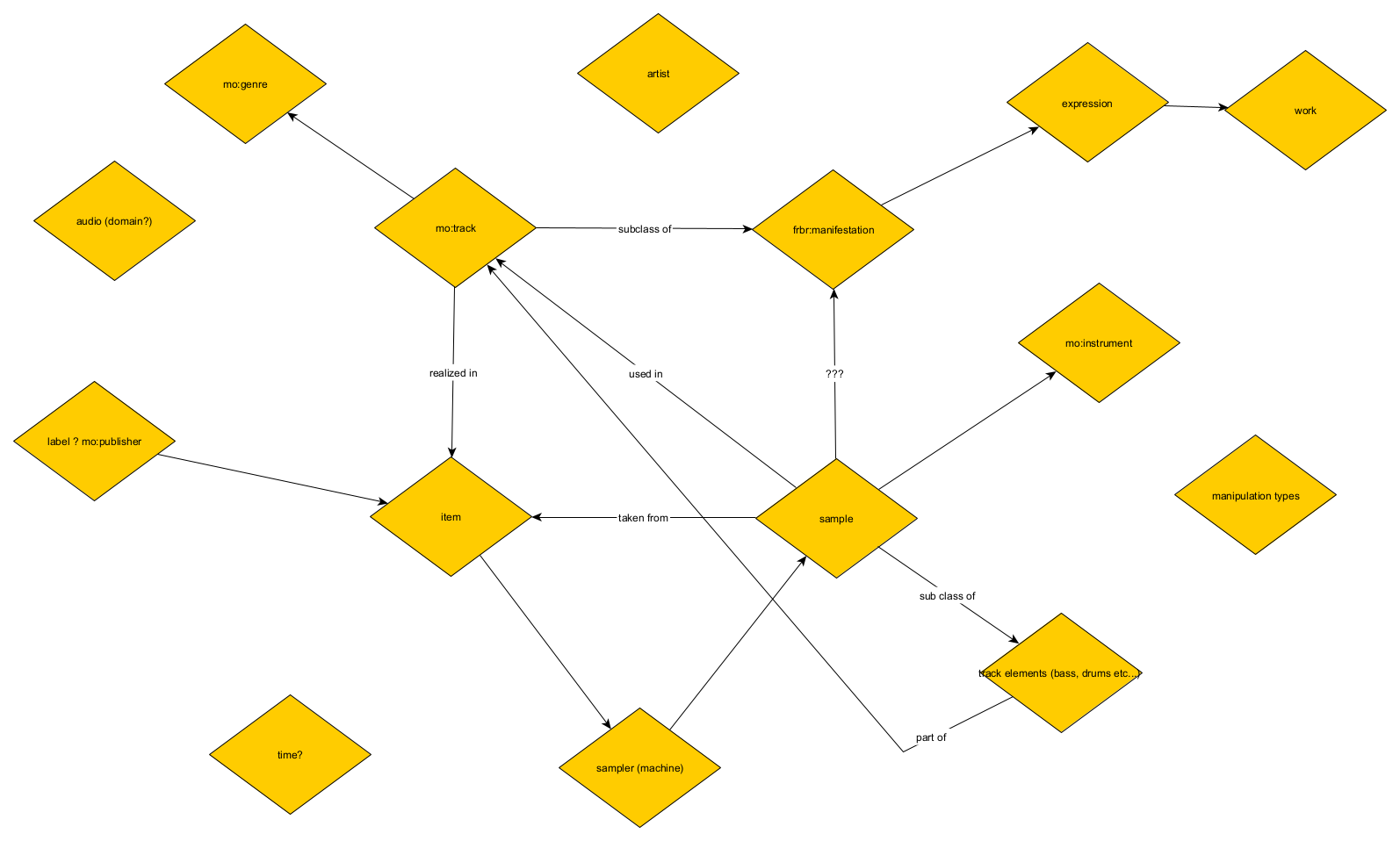
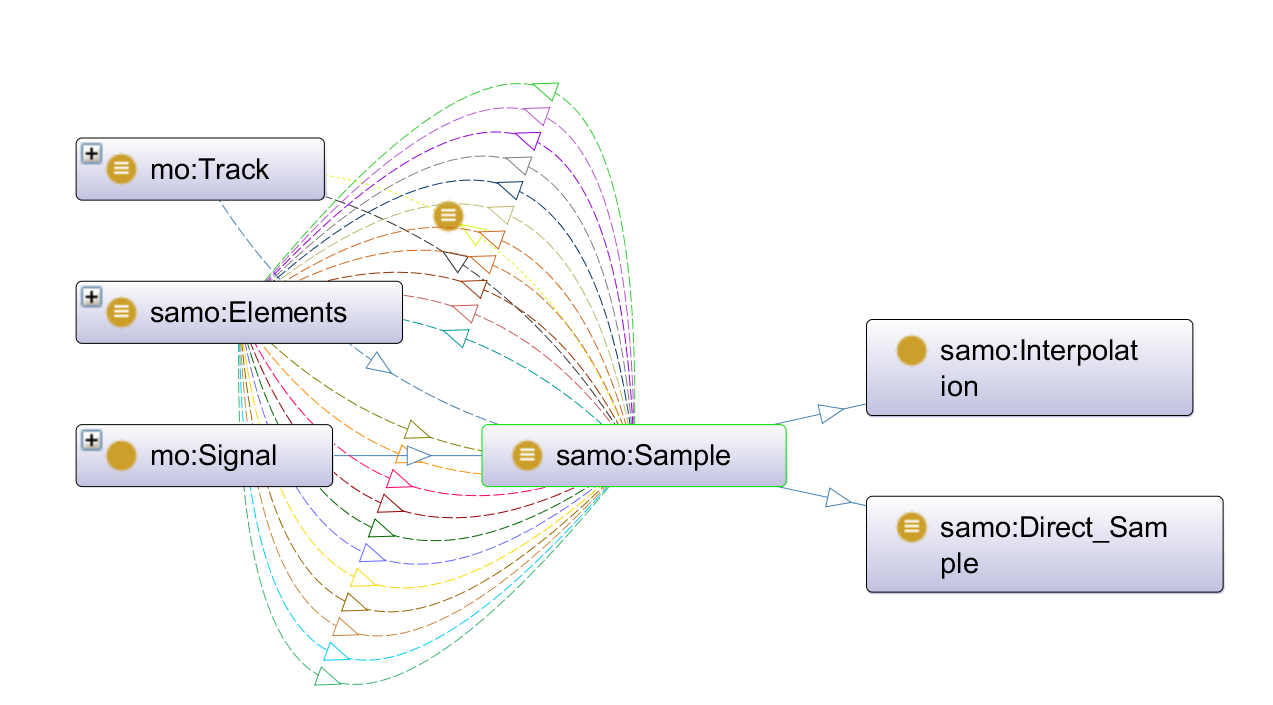
The first thing to emerge from this process was a set of key conceptual elements that we knew were needed within our model and which formed a loop of sorts: the idea of a track, the idea of a Manifestation as defined by FRBR (the publication/production of an Expression), the idea of a sample, and the interactions between sample and track. This can be seen in figure 1.
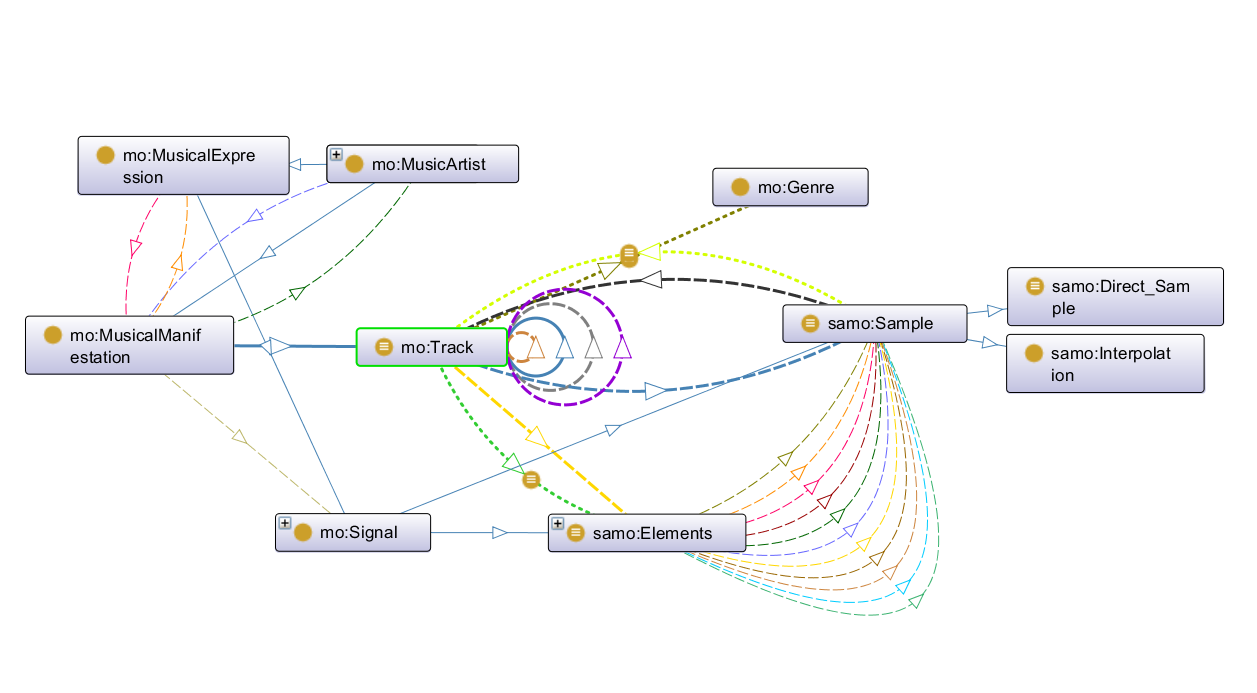
We then refined the map, as seen in figure 2, by adding and linking concepts from MO, the Event Ontology, and foaf. We also expanded on the ways in which sample and track interacted with each other by taking inspiration from how WhoSampled models sampling relationships using musical elements, which are part of a track, and the different types of sample (direct or interpolation). We also decided to enhance the model by adding different types of manipulation, which impact the way the elements are transformed into a sample, as this felt like a key conceptual idea that is not represented in WhoSampled (at least in their public facing data).
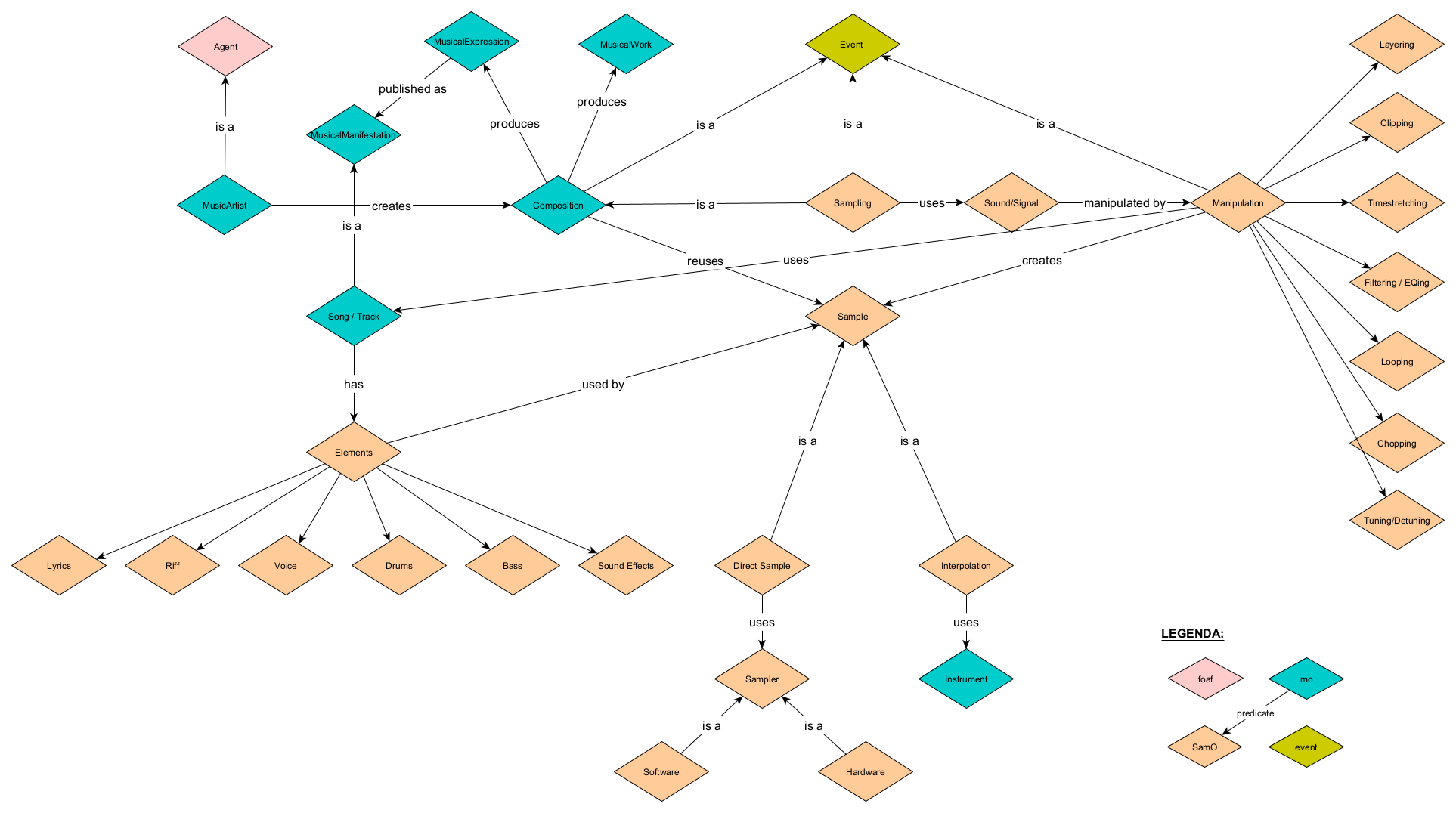
Documentation
Building the Ontology
Eventually we got to a point where we felt that it would be best to begin building the ontology as a way to stress test the validity of our conceptual map/model, in essence switching from our initial bottom-up approach to a top-down approach so that we could build the dataset based on the ontology. In doing this we realised that there was a potential issue in how we were reusing MO's classes and concepts as they related to the idea of sampling, which is at the heart of our ontology.
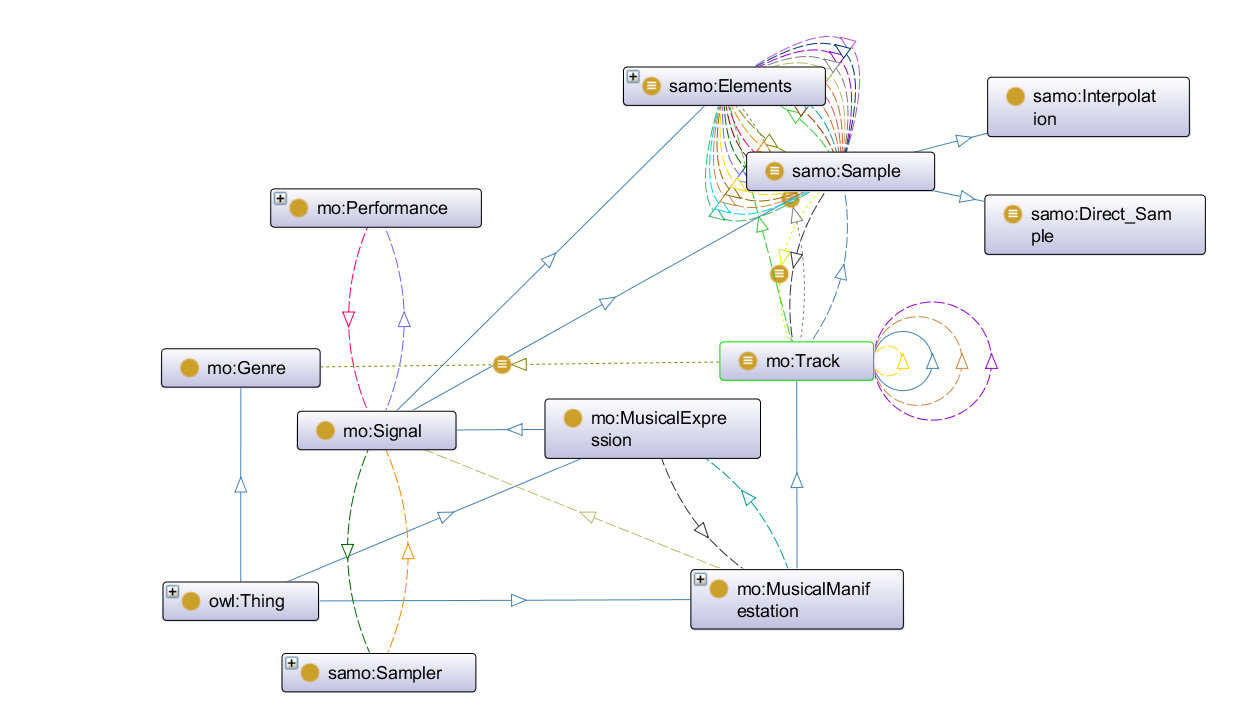
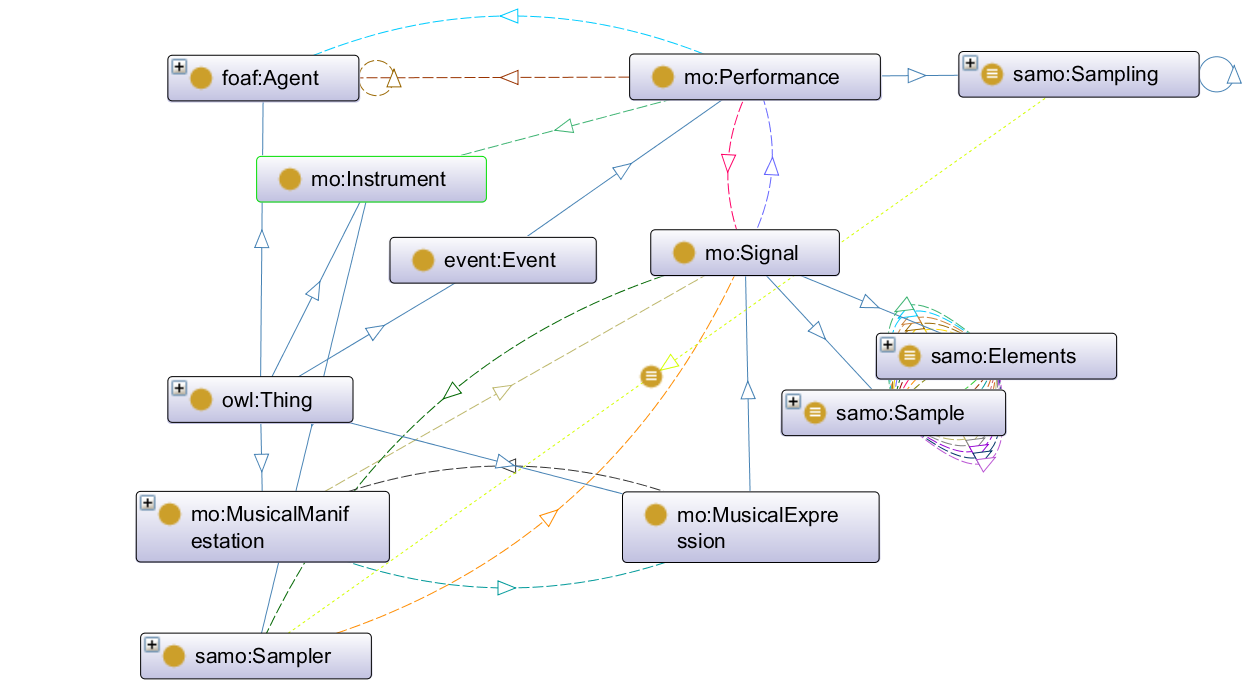
We debated whether the act of sampling should be considered as a sub-class of MO's composition, which clearly created some complications in how to link sampling to a track (see figure 2). This setup would also force us to reuse more of MO's framework which was clearly not designed for what we wanted to do. In the end, we decided to make sampling an event similar to how MO treats composition (using the Event Ontology) and make it a sub-class of MO's performance event class which is defined as an event "that might produce a sound" with input from agents and instruments. This was an ideal fit (see figure 4).
In turn, sampling was then linked to the Expression level via MO's existing properties for linking a performance to a signal, and then in turn we created two signal sub-classes (sample and elements) which formed the basis of what was needed for a sampling event (see figure 4). Lastly, these two sub-classes were linked to MO's track class, itself belonging to the Manifestation level. Therefore, we focused only on the Expression and Manifestation levels that MO borrows from FRBR and within those reused or created the necessary classes and properties to express the key conceptual elements we wanted (see figures 3 and 5).
With this structure in place we also borrowed the idea of a shortcut property from MO to allow the user two paths for connecting a song with the song that samples it: a long path that goes from Manifestation (source track) to Expression (elements of the source track) and then back to Manifesation (from elements to sample via manipulation, and from sample to new track); or a short path that links two tracks together using a simple self-referential property, samples/is_sampled_in. This was modelled on MO's records/recorded_as property, which we also reused in SamO as it bypasses the various steps in MO to directly link a signal to a performance, which in SamO links the act of sampling to the signals it creates (see figure 6).
After this we then debated whether or not the manipulation types should be considered as classes or properties. We tried both and ultimately properties proved best suited to the underlying conceptual idea that a manipulation allows the transformation of one class (elements) into another (sample), both of which belong to the parent class signal. This fits with MO's definition of a signal ("a master signal produced by a performance and a recording") and allowed us to maintain the needed connection between signal (Expression) and track (Manifestation). In the end, we settled on 10 different types of manipulation (sub-properties of manipulated_into/manipulation_of) that reflect some of the best known and standard practices such as looping, tuning, and scratching. It should be noted that ultimately a granular definition of how a sample was manipulated will always be a bit of a guessing game without direct input from the producer responsible for creating the sample. It's fair to assume that this is why WhoSampled does not indicate how samples have been manipulated, however we felt it was a worthy conceptual nuance to add to the ontology and that it may be useful to scholars and musicians alike should they want to detail exactly how tracks are transformed into samples.
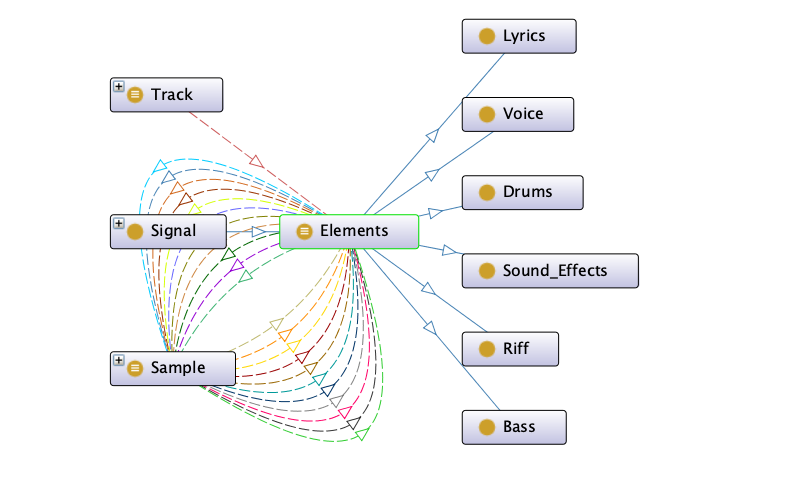
As for the elements class, we originally imagined it to be a sub-class of MO's track however after defining the sampling event as detailed above we realised that it made most sense as a type of signal, especially as MO considers a track to be a compilation of signals. The different elements sub-classes were borrowed from WhoSampled and we decided to keep "lyric" and "voice" with the idea that the former can be used whenever there is an intelligible lyric being used in the sample while the latter works for any sonic element that uses a voice as its source but may not refer to a specific lyric or may transform an existing lyrics into a new one, as is the case in the song Oh Timbaland within our dataset (see figure 7).
From MO we reused the genre class, which allows the association of a track with a musical genre via the genre property, and also tried to express logical limitations for the track class by stating that it should have at least one genre and one element (see below for more on that). We also reused MO's instrument class and created a new sub-class for the sampler as an instrument with a further two sub-classes to differentiate between digital and analog samplers. The difference between the two is subtle, essentially axed on which interface it uses as noted in the description for each class, and they both have historical grounding however in reality the difference between digital and analogue samplers is quite fluid. Any digital sampler requires some sort of analogue element to be used and many analogue samplers will use some sort of digital processing. These two classes should also be most useful for connecting any dataset using SamO with other ontologies that deal with music.
Two last points. Firstly, we limited SamO in terms of data properties as these are not essential to the ontology. We ultimately carried over the duration property from MO to describe the lenght of tracks (and which could also be used to describe the length of samples if needed) and created a release_year property, for a song, for the needs of our Competency Questions (MO doesn't have an equivalently useful property). Secondly, we also discussed what happens when a sample becomes an element, which is the case for tracks that use samples, but decided that this should be left for future development as we found it difficult to create the necessary logical conditions in the ontology. In fact we hit similar issues when trying to define restrictions for some of our classes. For example, we wanted to be able to express the idea that the sampling event requires manipulation with a sampler; that any individual of the element class could only be part of maximum 1 track; that the sample class was part of some track; that a direct sample required at least 1 manipulated element; and that a track needed at least 1 genre and 1 element. Ultimately we defined these restrictions/conditions as equivalences using Manchester syntax in Protégé but aren't sure that this is the correct way to do it. Perhaps, we should just accept that there are limits to what an ontology can express.
Classes & Sub-Classes
Object Properties
Data Properties
Dataset Individuals
Documentation
The Dataset
Once we had a working TBox we decided to create an ABox using the sample relationships selected at the beginning of the project (see full list below). We created a separate file using turtle syntax and described our 23 choices based on the publicly available information from WhoSampled as well as our own technical and historical knowledge to add details of sample manipulation (some of which has been simplified, see future development section for more on that), genre individuals, and one test individual for the sampler class.
Our selection of relationships allowed us to complete all our chosen Competency Questions, for example by giving us artists such as Miles Davis and Nina Simone who have been sampled multiple times and by giving us a range of source genres and dates. Some of the credited collaborations between vocalists on a song were ignored for the sake of simplicity however collaborations at the compositional level were kept (in particular for jazz songs). The dataset also includes one instance of a cover (Autumn Leaves) and a remix (Jazzy Sensation's Jazzy Mix). In our early conversations we had imagined using the ontology to also describe different types of songs related to sampling, such as covers and remixes, but ultimately decided to only describe the possibility of something being a cover. The remix is treated as a normal track.
The sample relationships we chose only related to one specific sample that a destination song might use, but it is in fact quite common for hip-hop and electronic music songs to make use of multiple samples. While we did not want to spend the time recreating all the samples for every song in our dataset, we did choose one — Manifest, by Gangstarr — as a test case and included all the samples for it as listed by WhoSampled. As mentioned in the future development section, one of the drawbacks of SamO — and as far as we can tell of any attempt at a detailed ontological breakdown of sampling — is that to describe sampling relationships requires the creation of new datapoints for every song element and resulting sample involved.
Both the dataset and the ontology are available as .ttl and .owl files in the data folder of SamO's GitHub repository.
- Bitches Brew -> Fattanza Blu (source)
- A Night In Tunisia -> Manifest (source)
- Fly Me To The Moon -> Splattitorium (source)
- Autumn Leaves -> Autumn Leaves (cover) (source)
- Caravan -> Jazzy Sensation (Jazzy Mix) (source)
- Cantaloupe Island -> Cantaloop (flip fantasia) (source)
- Skylark -> Survival of the Fittest (source)
- Mystic Brew -> Electric Relaxation + Mystic Bounce (source, source)
- Shadows -> It's a Jazz Thing (source)
- It Feels So Good -> Sticky Fingers (source)
- Django -> The Words (source)
- Just The Two of Us -> Just The Two of Us (source)
- So What -> Rimshot (intro) (Live) (source)
- Ain't Got No, I Got Life -> I've Got Life (source)
- Mr. Bojangles -> Jump Hi (source)
- I Want You -> Be Happy (source)
- Jungle Boogie -> The Doo-Bop Song (source)
- In A Silent Way -> Dopamina (source)
- Mister Magic -> Understanding (source)
- Aguas De Marco -> Girl From Alaska (source)
- Sinnerman -> Oh, Timbaland (source)
- Curtains -> Peng Black Girls (source)
Release
Final Competency Questions and Testing
Starting from the initial Competency Questions we had asked ourselves, and using what we learnt during development, we put together a list of 20 final CQs to test SamO with. Each of these CQ allowed us to ensure that all the key components of the ontology worked as intended. Each CQ was translated into a SPARQL query and executed using Protégé and the dataset file. These can be seen below.
Hover any CQ to see the logical components using the following legend: Logical implication | Class | Event | Relationship | Individual.
CQ #1
How many samples are in the song Electric Relaxation?
CQ #2
Which songs are sampled in the song Electric Relaxation?
CQ #3
Which jazz songs are used as samples?
CQ #4
How many songs contain a sample of It Feels So Good?
CQ #5
Which songs have sampled It Feels So Good?
CQ #6
Which songs released between 1970 and 1972 have been used as a sample?
CQ #7
Which songs by Nina Simone have been used as a sample?
CQ #8
Which elements from Mr. Bojangles are sampled in Jump Hi?
CQ #9
Which artist is the most sampled ?
CQ #10
Which song contains the highest number of samples?
CQ #11
Which songs use looped samples?
CQ #12
Which samples in Rimshot (Intro Live) are interpolations?
CQ #13
Which songs are covers?
CQ #14
How is the sample from Shadows manipulated in It's a Jazz Thing?
CQ #15
Which artist sampled Cantaloupe Island?
CQ #16
Who is sampled in The Words?
CQ #17
Which artists have written jazz songs?
CQ #18
Which producer sampled Nina Simone?
CQ #19
Which sampler did DJ Premier use on Manifest?
CQ #20
Which songs released between 1970 and 1972 have been used as a sample in a hip-hop song?
Release
Fixing and Releasing
An iterative process
The development of SamO (as detailed in the Documentation section) was an iterative process with multiple passes on both the terminology (TBox) and assertion (ABox) components to adjust and refine concepts as well as errors and redundancies that arose through testing. Protégé was used as the primary software for the construction of both TBox and Abox and SPARQL testing. Logic reasoners within Protégé and the online service Oops were used to ensure consistency and structural integrity.
Releasing and publishing
We decided to release and publish SamO by following the examples of MO. As such we are using a persistent URL structure similar to MO (/ontology/samo/) and we have detailed the SamO classes and properties in a similar fashion as MO. However, we have opted to release SamO using a CC BY-SA 4.0 license to enable its spread, evolution, and reuse.
Unlike MO, we used WIDOCO to publish SamO's specification, which enables both textual and visual representations of the ontology in a W3C style.
Possible future development
- One of the main points that arose during the last testing phases of the development was the difficulty in describing exactly what is happening sonically during the transformation process between song element and sample. Sampling is ultimately a fuzzy practice. While we tried our best to develop SamO to enable a user to describe this, we were also limited by our own knowledge of music production and the available information on a given track. As such we suggest that a possible point for future development is to involve musicians, producers, and engineers in a conversation about how best to describe this transformational process and use this to refine the manipulation properties and make any needed adjustments to the ontology.
- Another point for future development would be to stress test the ontology with larger datasets to see if anything is missing or can be improved upon. In creating our dataset we did notice that in its current form, SamO requires the creation of additional data points (a source song's elements and a destination song's samples) which isn't ideal. One solution might be to use automation to create these, while another might be to combine the use of an ontology like SamO with metadata and Machine Learning.
- As detailed in the Documenation section, we recommend that future development also look at how to differentiate between song element and sample when the latter becomes an element of a new song, which would in turn allow for a way to describe remixes as a specific type of song. One simple approach might be via logical equivalence, such that a sample is equivalent to an element if an element has first been manipulated into a sample and used in a track.

About
This project was developed as the final examination for the Knowledge Representation and Extraction course taught by A. Nuzzolezze and A. Gangemi, University of Bologna, a/y 2020-2021.
The team

Laurent Fintoni
"French, but exiled abroad for so long he now writes in English." Alleged author. Would be archivist. We care more than they hate.

Ilaria Rossi
Currently exploring the DH realm and philosophy as a way of life.
Early music, philosophy of language and logic lover.